Enrollment Nerdery
A place to collect my thoughts on data analysis within Enrollment Management. Dare I call it Enrollment Science?

TL:DR
Below I use Prismatic’s API to tag the mission statements of approximately 500 colleges in the U.S. in order to evaluate the “focus” of each, which I define as the topics extracted from the API. In addition, I also consider the competitive nature of various schools, commonly refered to as the “Competitor Set”.
Out of the gate, I considered more than 1,000 schools for this study. In the end, I only kept institutions with clean data, that is, no missing information across all of the data I collecteted. Simply, I threw out a ton of data, but that’s ok, this is more an exploration to think do the following:
How “accurate” is the Interest Graph prediction of the topics contained within the mission statements?
It’s important to note that there are two sources of error; the API could mis-classify the mission statement, or perhaps the language of the mission statement is vague.
Are topics related to admissions performance?
This isn’t really a pratical business problem, but hey, if we have the data, why not give it a shot?
Quick Side Note
This is intended to be a quick post on playing around with the recently released Prismatic Interest Graph API. I encourage you to take a few minutes to scan the blog post; very cool stuff!
For me, the timing couldn’t be better, as I have been thinking alot about graphs in the recent months, and the idea of being to assign topics to text makes this all the better.
As I am wrapping up the work on this post, I noticed they just enhanced the API to search for related topics. Awesome! I put together a basic R Package prismaticR. Let me know what you think!
I am going to use the API to extract topics from a fairly specific set of institutions’ mission statements. Needless to say, a mission statement says a lot about an institution and what they stand for. My idea is to use the API to extract the larger themes and see if the intent matches “reality”, as defined by the results of the API call.
- What institutions tend to focus on the same topic?
- Are certain topics associated with “higher profile” institutions?
- Based on the topics extracted, is there evidence to suggest that some mission statements miss the mark?
I encourage you to head over to my Github repo to review my code where all data collect is done within R, no point-and-click necessary! By no means is my code pristine, but hopefully it can help you out if you are learning R.
The Data
First, a talk about the schools that I am including in this work. Here are my criteria:
- The institution is located in the domestic US (and is not a military institution)
- Public 4-year and Private, 4-year not-for-private degree-granting institutions
- Enrolled more than 300 first-year students
This is a pretty specific set of institutions, and certainly does not reflect the “average” college in the U.S, but my aim is to include as many “traditional colleges and universities” as possible.
After getting this list of about 1,000 schools, I crawled each institutions’ College Navigator page to parse out URL for their mission statement. Not all institutions present a URL, so I removed any institution that included a mission statement in text-form on the profile page. I know this isn’t ideal, but I wanted to throw data together quickly.
From there, I used the Interest Graph API to tag each mission statement with predicted “topics.” The API was able to make successful requests on a large number of pages, but there were a handful of instances where the API returned null results, or more likely, the API was not able to extract topics due to insuffient text. I also removed these schools from consideration.
Next, I grabbed some basic admission metrics for these schools from IPEDS. More specifically, I included things like admit rate (the % of applicants that were offered admission), SAT metrics, and school size. There are a few other data points, so take a look at my code to see which IPEDS variables I included. I didn’t want to go down the rabbit’s hole and analyze every metric, but I grabbed a handful available just in case.
Lastly, of those institutions that “made the cut”, I included what some might consder their competitive set. A few notes on this:
- I crawled a popular college search site to extract each institution’s “Similar” colleges. It’s just one source of data, but they seem ok to me.
- Again, I only included the competitive information for the schools that had complete data from above
It’s worth noting that not all institutions will have competitive data. This could be due to the fact that my crawler didn’t parse everything properly, or, the site did not display this information, which I verififed on a few of the cases.
To make this analysis possible, I used RNeo4j to put these datasets into a graph, using the data model shown below:
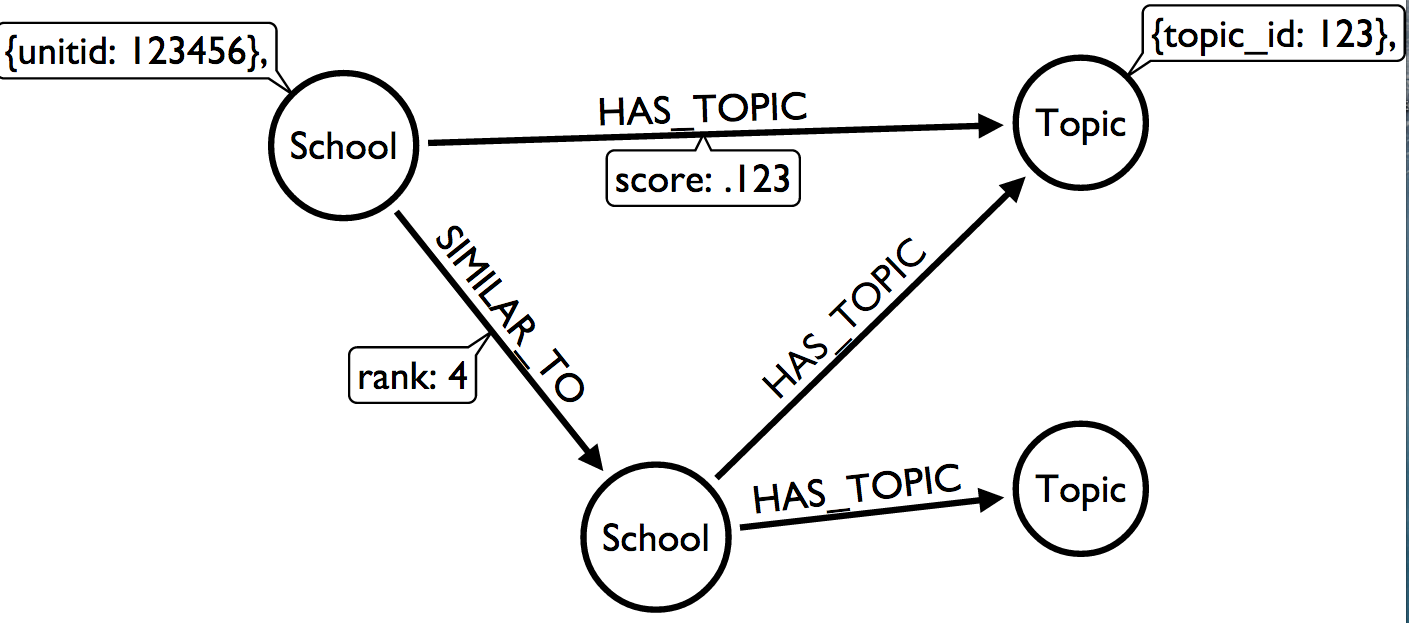
Our dataset has two types of nodes, School and Topic. Schools are connected to topics through a HAS_TOPIC relationship, with a value that I assume is the API’s confidence for the topic. Schools are also connected to other Schools through a SIMILAR_TO relationship, with a rank value. A rank of 1 implies the closest competitor.
Descriptive Stats
Here are some quick cypher queries to explore the data we have loaded into the database.
Summary of the graph
summary(graph)
This To That
1 School HAS_TOPIC Topic
2 School SIMILAR_TO School
How many nodes are in the database
cypher(graph, "MATCH (n) RETURN COUNT(n)")
COUNT(n)
1 803
Count of distinct node types
query = "
// counts by distinct node type
MATCH n
RETURN DISTINCT LABELS(n), COUNT(n)
"
cypher(graph, query)
LABELS(n) COUNT(n)
1 Topic 319
2 School 484
Count of relationship types
cypher(graph, "MATCH ()-[r]->() RETURN type(r), count(*)")
type(r) count(*)
1 HAS_TOPIC 2701
2 SIMILAR_TO 5468
Explore the Graph
The table below shows 10 rows of data were schools are connected to topics.
| school | name | topic | score |
|---|---|---|---|
| 100663 | University of Alabama at Birmingham | Budgets and Budgeting | 0.5017 |
| 100663 | University of Alabama at Birmingham | Birmingham, Alabama | 0.5091 |
| 100663 | University of Alabama at Birmingham | Higher Education | 0.5124 |
| 100663 | University of Alabama at Birmingham | Colleges and Universities | 0.5603 |
| 100751 | The University of Alabama | Colleges and Universities | 0.6104 |
| 100751 | The University of Alabama | Alabama | 0.6066 |
| 100751 | The University of Alabama | Mobile, Alabama | 0.5434 |
| 100751 | The University of Alabama | Research | 0.5433 |
| 100751 | The University of Alabama | Higher Education | 0.5294 |
| 100751 | The University of Alabama | Montgomery, Alabama | 0.5261 |
It’s important to note that this is only half the picture. If you refer back to the graph model above, notice that we are only looking at the connections between School and Topic, when in reality, we also have edges between School and School. This is demonstrated below.
| From School | To School | Rank |
|---|---|---|
| University of Alabama at Birmingham | The University of Alabama | 1 |
| University of Alabama at Birmingham | Auburn University | 2 |
| University of Alabama at Birmingham | University of South Alabama | 3 |
| University of Alabama at Birmingham | Jacksonville State University | 6 |
| University of Alabama at Birmingham | University of North Alabama | 10 |
| University of Alabama at Birmingham | Mississippi State University | 13 |
| University of Alabama at Birmingham | University of Montevallo | 16 |
| University of Alabama at Birmingham | University of Mississippi | 18 |
| University of Alabama at Birmingham | The University of Tennessee-Knoxville | 21 |
| University of Alabama at Birmingham | Florida State University | 22 |
In the table above, we are looking at the connections between schools, where From is considered SIMILAR_TO To. The column rank indicates competitor strength, where Rank 1 is considered he most “similar” school. We could debate the definition of “similar” all day long, so I will spare that for a later blog post.
It might help to put a picture to the data …
While you can already start to see some interesting patterns, we are only viewing this graph as if there were only one node type …
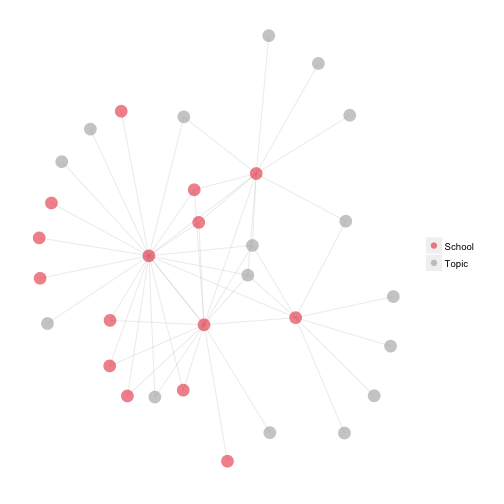
In the plot above, for the nodes when doing a before-and-after plot, but I am not sure how you can accomplish that with using ggnet.
Regardless, I hope the second plot - the same graph as above - starts to paint a picture of the type of data we can play around with.
Analysis
Let’s start to ask some questions from the database.
Topic Distribution
What are the most popular topics? The percentage indicates the fraction of mission statements having that topic. 100% would indicate every mission statement was tagged with that topic by the API.
| Topic | Times_Listed | Pct_Listed |
|---|---|---|
| Colleges and Universities | 366 | 0.7562 |
| Higher Education | 291 | 0.6012 |
| International Education | 157 | 0.3244 |
| Graduate Schools and Students | 124 | 0.2562 |
| Academic Freedom | 95 | 0.1963 |
| Education | 94 | 0.1942 |
| Education Reform | 89 | 0.1839 |
| Humanities | 87 | 0.1798 |
| Community Colleges | 73 | 0.1508 |
| Education and Schools | 67 | 0.1384 |
You can see that even in the top 10, the concentration of topics starts to fall off fast. For example, of the 484 schools in the dataset, approximately 80% had language in the mission statement that API clearly understood as being about Colleges and Universities. Education, ranked 6th, was tagged in 94 mission statements, or just under 1 in every 5 schools.
To me, this highlights that each mission statement has a focus, which is a good thing, but it might help to understand topic assignment. How many topics are typically included in an institution’s mission statement?
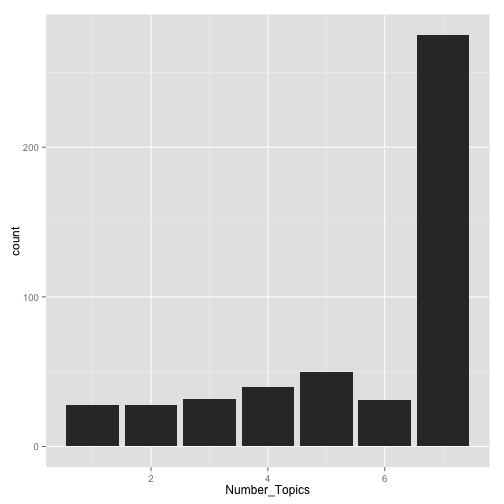
The mission statements had up to 7 topics, with the majority of schools being tagged 7 times by the API.
What now?
We can see that a large share of the schools’s mission statements were tagged with 7 topics. Given what we have just seen, two interesting questions have emerged.
- What is it about the insitutions that do not clearly write their mission statements in a way that the API would not identify the core higher ed topics?
- Are there relationships between topics and admission performance and/or an institituion’s competitive set. More specifically, do institutions competing with one another have similar missions? If we can extract the topics to understand the focus of an insitituion, is there evendince that some schools do better than others?
Basic Admission Stats for the Top 10 Topics
For simplicity sake, let’s limit the admissions performance to the top 10 topics.
| Topic | ape | sat75 | iqr | apps | enrollment | total |
|---|---|---|---|---|---|---|
| Colleges and Universities | 6.678 | 1189 | 209.9 | 8736 | 1425 | 366 |
| Higher Education | 6.502 | 1178 | 210.2 | 9240 | 1520 | 291 |
| International Education | 6.238 | 1166 | 208.2 | 8869 | 1528 | 157 |
| Graduate Schools and Students | 6.884 | 1172 | 209.1 | 9083 | 1332 | 124 |
| Academic Freedom | 7.002 | 1215 | 209.4 | 11395 | 1633 | 95 |
| Education | 7.53 | 1203 | 205 | 8423 | 1187 | 94 |
| Education Reform | 7.123 | 1209 | 203.5 | 7463 | 1114 | 89 |
| Humanities | 7.402 | 1242 | 209.5 | 10715 | 1455 | 87 |
| Community Colleges | 7.607 | 1203 | 203.9 | 5931 | 854.1 | 73 |
| Education and Schools | 5.97 | 1154 | 211.1 | 7428 | 1326 | 67 |
For reference:
ape= # applications per enrolled studentsat75= the 75th percentile for students submitting the SATiqr= the middle 50% based on the SAT 75th and 25th percentilesapps= number of first year applicationsenrollment= number of first year students enrolledtotal= the number of schools whose mission statement was determined to have this topic by the Prismatic Interest Graph API
I fully admit that you should take extreme caution when trying to use the results of the API for anything other than exploratory at this point. First off, admittedly Prismatic says that their API is in ALPHA phase.
Top 2 Topics
The query below puts the schools into one of two buckets; whether or not their mission statement was tagged with one of the top 2 topics.
- Colleges and Universities, or
- Higher Education
## the query
query = "
MATCH (s1:School) -[r1:HAS_TOPIC]-> (t1:Topic)
WHERE EXISTS((s1)-[:HAS_TOPIC]->(:Topic {topic:'Colleges and Universities'})) OR
EXISTS((s1)-[:HAS_TOPIC]->(:Topic {topic:'Higher Education'}))
RETURN 'has topic' as topic,
avg(s1.ape) as ape,
avg(s1.sat75) as sat75,
avg(s1.iqr) as iqr,
avg(s1.applcn) as apps,
avg(s1.enrlft) as enrollment,
count(DISTINCT s1) as total_rels
UNION
MATCH (s2:School) -[r2:HAS_TOPIC]-> (t2:Topic)
WHERE NOT(EXISTS((s2)-[:HAS_TOPIC]->(:Topic {topic:'Colleges and Universities'})) OR
EXISTS((s2)-[:HAS_TOPIC]->(:Topic {topic:'Higher Education'})))
RETURN 'no topic' as topic,
avg(s2.ape) as ape,
avg(s2.sat75) as sat75,
avg(s2.iqr) as iqr,
avg(s2.applcn) as apps,
avg(s2.enrlft) as enrollment,
count(DISTINCT s2) as total_rels
"
dat = cypher(graph, query)
pander(dat)
| topic | ape | sat75 | iqr | apps | enrollment | total_rels |
|---|---|---|---|---|---|---|
| has topic | 6.667 | 1188 | 210.8 | 9070 | 1451 | 394 |
| no topic | 6.507 | 1208 | 217.8 | 7599 | 1317 | 90 |
has_topic= institutions where the mission statement includes the topics aboveno_topic= the institutions were not connected to those topics
While the stats are just in aggregate, but there is bit of a gap in the 75th percentile scores, as well as a gap of 1600 more apps on average. There is certainly more that you could do with this, but I just wanted to highlight one way you could slice the data.
School Competition and Mission Statement Topics
I wanted to highlight how easy it is to answer some really complex questions using Neo4j. The table below looks isolates Harvard, finds the institutions which they are SIMILAR_TO, and collects the topics found within each school’s mission statements.
query = "
MATCH (s:School {unitid: 166027}) -[:HAS_TOPIC]-> (t:Topic)
RETURN s.instnm as school, COLLECT(t.topic) as topics
UNION
MATCH (s:School)-[:SIMILAR_TO]->(y:School)-[:HAS_TOPIC]->(t:Topic)
WHERE s.unitid = 166027
RETURN y.instnm as school, COLLECT(t.topic) as topics
"
dat = cypher(graph, query)
pander(dat)
| school | topics |
|---|---|
| Harvard University | Harvard University, Colleges and Universities, Education Reform, Higher Education, Graduate Schools and Students, Ivy League, Scholarships and Fellowships |
| Duke University | Duke University, Education, Medicine, Adult Education, Colleges and Universities |
| Dartmouth College | Colleges and Universities, Ivy League, International Education, Culture, Community Colleges, The New School, Graduate Schools and Students |
| Georgetown University | Colleges and Universities, Georgetown University |
| Massachusetts Institute of Technology | Humanities, Graduate Schools and Students, Environmental Science, Education, Colleges and Universities, Higher Education, Massachusetts Institute of Technology |
| Princeton University | Higher Education, Colleges and Universities, Humanities, Academic Freedom, Environmental Science, Library Science |
| University of California-Los Angeles | Academic Freedom, Higher Education, Humanities, Society, Research, Education, Gender |
| Cornell University | Colleges and Universities, Humanities, Academic Freedom, Higher Education, International Education, Culture, Gold Standard |
| University of Pennsylvania | University of Pennsylvania, Pennsylvania, Pittsburgh, Pennsylvania |
| Boston University | International Education, Colleges and Universities, Boston, Scholarships and Fellowships, Academic Freedom |
| Carnegie Mellon University | Carnegie Mellon University, Creativity |
I find it interesting that in some cases, the institution itself is a topic within the Prismatic API.
Summary
I am still new to Neo4j to solve business problems, but hopefully you found at least some part of this post intersting or helpful. Admittedly there isn’t a lot of practical use-cases shown above, but the Prismatic API and Neo4j are fun to play around with.
comments powered by Disqus